
CERBERO Interoperability Framework
The CERBERO Interoperability Framework (CIF) leverages on a simplified ontology-based data integration approach to combine data or information from multiple heterogeneous sources. The main goal behind CIF is to enable interoperability between computing services/processing entities in an efficient and transparent way.
CIF allows each participant to publish or retrieve data in their own format and data model paradigm – it follows the mote: “Write in your format, I read in my format”. The CIF platform is responsible to efficiently merge and re-format information according to the need of each participant. When using CIF, processing entities do not have to care about understanding and re-structuring the data formats of other entities. This makes processing chains more efficient – due to less overhead on data translation – and much more composable – as data interfaces become more flexible.
We envision two scenarios that can benefit from CIF. The first one is the sharing of system model among several tools: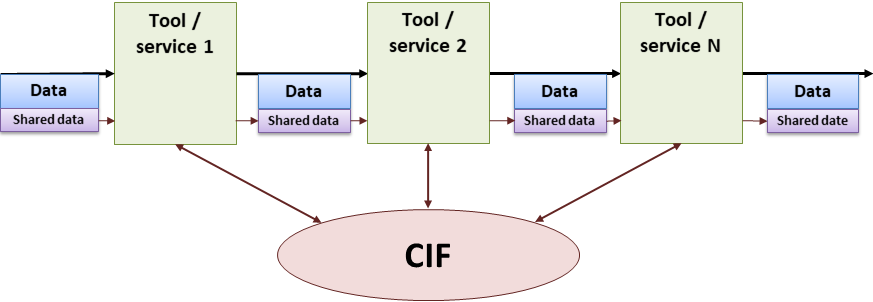
CIF intermediates the aggregation of model’s information from different sources and its efficient/transparent retrieval by (consumer) tools. For these contexts, CIF is specially valuable on exchanging/upkeeping (historical) data.
The second scenario is enriching stream (and data-block) metadata information along the processing chain:
In this case, data between tools travels along the processing chain. CIF enables heterogeneous tools to enrich the system model in their own format. At each step, CIF can be used to reconstruct/combine/interpret the information added by different sources into one merged model, which can be reshaped for the task at hand.
In more details, the key feature of CIF is flat model representation based on schema provided by tools provider for the interoperability purposes in two-layered structure that separates instances with their properties from classes. Each instance represents a thing that possess one or more properties, and a property can possess a value, another object or carry decisions. Classes are implemented extending classification-by-property paradigm, where a predefined set of properties and filters provides class definition. Since information available at system level are relevant at lower levels, instances and properties in a model structure are inter-linked to allow navigation from one property in the system to another across different layers. This allows, in many cases, to replace classical model-to-model
transformation by aliases between tools namespaces representing the same things or properties or making property-based aggregations independent of tools’ schemas.
To summarize, in order to efficiently interpret, store, merge and exchange data in open world with many analysis and optimization tools, CIF proposes how to standardize data schema and model exchange operations in a robust and efficient way.
 © 2017 CERBERO | All Rights Reserved |
Project ID: 732105,
Funded under: H2020-EU.2.1.1. - INDUSTRIAL LEADERSHIP - Leadership in enabling and industrial technologies - Information and Communication Technologies (ICT).
© 2017 CERBERO | All Rights Reserved |
Project ID: 732105,
Funded under: H2020-EU.2.1.1. - INDUSTRIAL LEADERSHIP - Leadership in enabling and industrial technologies - Information and Communication Technologies (ICT).